DAY 37 Kubernetes Important interview Questions.
Kubernetes Important interview Questions.
DAY 37
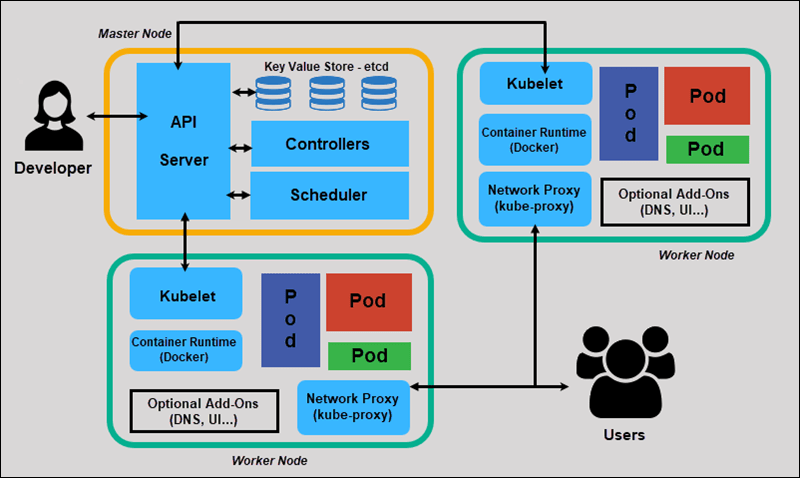

Q1 What is Kubernetes and why it is important?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Containers are lightweight, portable, and efficient units that package an application and its dependencies, ensuring consistency across different environments.
Here are some key aspects of Kubernetes and why it is important:
Container Orchestration:
- Kubernetes provides a framework for automating the deployment, scaling, and management of containerized applications. It abstracts away the underlying infrastructure, allowing developers and operators to focus on application logic rather than the intricacies of managing individual containers.
Scalability:
- Kubernetes allows applications to scale easily by dynamically adjusting the number of running containers based on demand. This ensures optimal resource utilization and performance.
Automated Deployment and Rollbacks:
- Kubernetes facilitates the automated deployment of applications through declarative configuration. It can roll back to previous versions if issues are detected during deployment, ensuring reliability and minimizing downtime.
Service Discovery and Load Balancing:
- Kubernetes provides built-in mechanisms for service discovery and load balancing. Services can be easily discovered and accessed by other components within the cluster, and load balancing helps distribute incoming traffic across multiple instances of a service.
Resource Utilization and Optimization:
- Kubernetes helps in efficient resource utilization by intelligently placing containers on nodes based on available resources and constraints. This ensures that workloads are distributed evenly across the cluster.
Declarative Configuration:
- Kubernetes allows users to define the desired state of their applications through declarative configuration files (YAML). The platform then works to maintain this desired state, automatically making adjustments as needed.
Container Orchestration Ecosystem:
- Kubernetes has a large and active ecosystem of tools, extensions, and services that complement its capabilities. This includes monitoring solutions, logging frameworks, networking plugins, and more.
Multi-Cloud and Hybrid Cloud Support:
- Kubernetes is designed to be cloud-agnostic, allowing applications to be deployed consistently across different cloud providers or on-premises environments. This flexibility is crucial for organizations with multi-cloud or hybrid cloud strategies.
Community and Industry Standard:
- Kubernetes has gained widespread adoption and has a vibrant community of contributors and users. It has become a de facto standard for container orchestration, making it easier for organizations to find talent and tools that integrate with the platform.
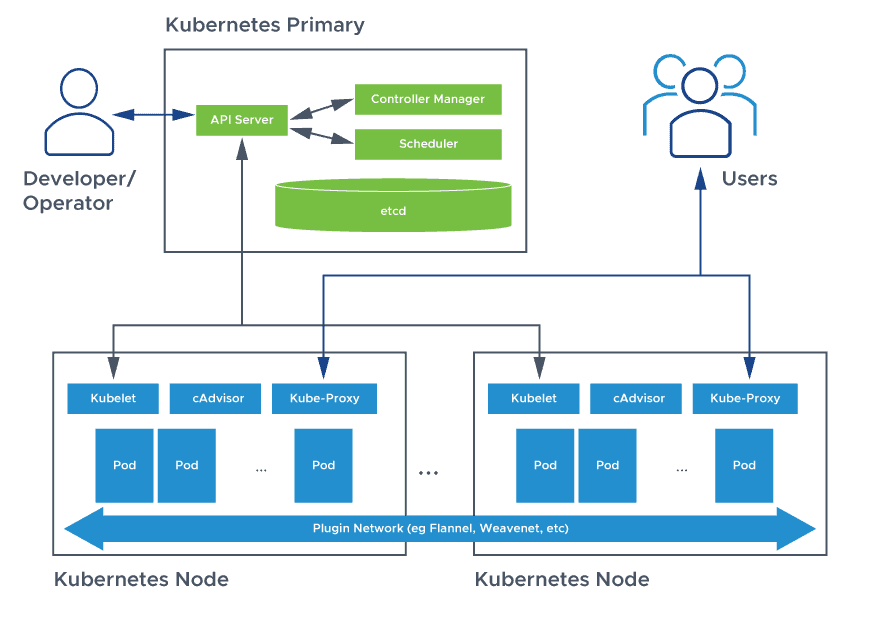
Q2What is difference between docker swarm and kubernetes?
Docker Swarm and Kubernetes are both container orchestration platforms, but they have some key differences in terms of architecture, features, and philosophy. Here are some of the main distinctions between Docker Swarm and Kubernetes:
Origin and Community Support:
Docker Swarm: Docker Swarm is part of the Docker ecosystem and is tightly integrated with Docker. It is generally considered simpler to set up and get started, making it a good choice for users who are already familiar with Docker.
Kubernetes: Kubernetes is an open-source project developed by Google and later donated to the Cloud Native Computing Foundation (CNCF). It has a larger and more diverse community, resulting in a rich ecosystem of tools and extensions.
Architecture:
Docker Swarm: Swarm follows a simpler architecture, and its components are tightly integrated with Docker. It uses a manager-worker model, where nodes are either managers or workers, and the manager nodes handle orchestration.
Kubernetes: Kubernetes has a more complex architecture with multiple components such as the Master (which includes API server, controller manager, and scheduler) and Nodes (which run containers and a kubelet to communicate with the master).
Declarative vs. Imperative Configuration:
Docker Swarm: Swarm often uses an imperative approach for configuration, where you specify the desired state and Swarm tries to achieve it.
Kubernetes: Kubernetes follows a declarative approach, where users define the desired state in YAML configuration files, and Kubernetes continuously works to ensure the current state matches the desired state.
Networking:
Docker Swarm: Swarm uses an overlay network for communication between containers across nodes. It simplifies networking but may not offer as many advanced features as Kubernetes.
Kubernetes: Kubernetes provides a more flexible networking model, allowing users to choose from various network plugins. This flexibility is beneficial for complex networking scenarios.
Service Discovery and Load Balancing:
Docker Swarm: Swarm includes built-in service discovery and load balancing. It automatically assigns a DNS name to each service, making it easy to discover and access services.
Kubernetes: Kubernetes also provides service discovery and load balancing, and it includes more advanced features, such as Ingress controllers for managing external access to services.
Scaling:
Docker Swarm: Swarm supports auto-scaling but may be considered simpler compared to Kubernetes. Scaling can be achieved by adjusting the desired replica count for a service.
Kubernetes: Kubernetes has more sophisticated auto-scaling options and supports both horizontal and vertical scaling. It can scale based on metrics such as CPU usage or custom metrics.
Ecosystem and Extensibility:
Docker Swarm: Docker Swarm has a smaller ecosystem compared to Kubernetes. While it covers essential functionalities, users may find fewer third-party tools and integrations.
Kubernetes: Kubernetes has a large and diverse ecosystem with a wide range of tools, plugins, and extensions. This extensive ecosystem contributes to its popularity and adaptability in various scenarios.
Q 3 How does Kubernetes handle network communication between containers?
Kubernetes provides a flexible and extensible networking model that allows containers within a cluster to communicate with each other. Here are key components and aspects of how Kubernetes handles network communication between containers:
- Pods:
· In Kubernetes, the basic unit of deployment is a Pod. A Pod can contain one or more containers that share the same network namespace, allowing them to communicate with each other using localhost.
- Cluster IP:
· Each Pod in Kubernetes is assigned a unique IP address within the cluster. Containers within the same Pod can communicate with each other using this IP address and the loopback interface.
- Service:
· Services in Kubernetes provide a way to expose a group of Pods as a network service. A Service has a stable IP address and DNS name that other parts of the application can use to communicate with the Pods associated with the service.
· Cluster-internal communication between services is often handled using the Cluster IP, which is an internal IP assigned to the service.
- Service Discovery:
· Kubernetes provides built-in service discovery. Containers within the cluster can discover and communicate with services using DNS names. When a Service is created, a DNS entry is automatically created, allowing other services to reach it using its DNS name.
- Network Plugins and CNI:
· Kubernetes supports various network plugins that implement the Container Network Interface (CNI) specification. CNI plugins manage the network namespace of containers and define how networking is implemented within the cluster.
· Common CNI plugins include Calico, Flannel, Weave, and others. These plugins may use overlay networks, direct routing, or other techniques to facilitate communication between containers across nodes.
- Pod-to-Pod Communication:
· Pods can communicate directly with each other, even if they are on different nodes, thanks to the networking capabilities provided by the chosen CNI plugin. Kubernetes ensures that traffic is properly routed between nodes.
- Ingress Controllers:
· Ingress controllers manage external access to services within the cluster. They handle external HTTP and HTTPS traffic, routing requests to the appropriate services based on defined rules. Ingress controllers can also provide features like load balancing and SSL termination.
- Network Policies:
· Kubernetes allows the definition of Network Policies to control the communication between Pods. Network Policies specify rules for incoming and outgoing traffic, allowing fine-grained control over which Pods can communicate with each other.
- External Connectivity:
· Kubernetes can also manage external connectivity. Services of type
Load Balancer can be used to expose a service externally, and external traffic can be directed to the appropriate Pods within the cluster.
Q 4.How does Kubernetes handle scaling of applications?
Kubernetes provides robust mechanisms for scaling applications, allowing users to scale their workloads dynamically based on demand. There are two primary types of scaling in Kubernetes: horizontal scaling and vertical scaling.
- Horizontal Pod Autoscaling (HPA):
· Horizontal Scaling: This type of scaling involves adjusting the number of instances (Pods) of a particular application or service. It's often referred to as "scaling out" or "adding more instances."
· Horizontal Pod Autoscaling (HPA): HPA is a feature in Kubernetes that automatically adjusts the number of running Pods based on observed CPU utilization or other custom metrics. With HPA, you can define target metrics, and Kubernetes will scale the number of replicas up or down to meet those targets.
· Example HPA definition based on CPU utilization:
Vertical Pod Autoscaling (VPA):
· Vertical Scaling: This involves adjusting the resources allocated to individual Pods, such as increasing or decreasing CPU and memory limits. It's often referred to as "scaling up" or "scaling down."
· Vertical Pod Autoscaling (VPA): VPA is a feature that automatically adjusts the CPU and memory resource limits for Pods based on their historical usage. VPA helps ensure that each Pod gets the resources it needs without over-provisioning.
· Example VPA definition:
Manual Scaling:
· Users can also manually scale the number of replicas of a Deployment or StatefulSet using the kubectl scale command. For example:
- Cluster Autoscaler:
· The Cluster Autoscaler is an optional component that automatically adjusts the size of the cluster by adding or removing nodes based on resource requirements and constraints.
· It helps ensure that there are enough resources in the cluster to accommodate the desired number of Pods.
- Custom Metrics and External Metrics:
· In addition to CPU and memory metrics, Kubernetes supports custom and external metrics for autoscaling. This allows users to define their own metrics based on application-specific requirements.
Q 5.What is a Kubernetes Deployment and how does it differ from a ReplicaSet?
In Kubernetes, a Deployment and a ReplicaSet are both abstractions that help manage and ensure the availability and scaling of containerized applications. Let's explore each concept and highlight the differences:
Deployment:
- Purpose:
· Deployment: The primary purpose of a Deployment is to declare how applications should be deployed, updated, and rolled back. It provides declarative configurations for defining the desired state of the application.
- Declarative Updates:
· Deployment: Deployments support declarative updates to applications. You define the desired state in a YAML file, and the Deployment controller takes care of making the necessary changes to achieve and maintain that state.
- Rolling Updates and Rollbacks:
· Deployment: Deployments facilitate rolling updates, allowing you to change the application's image or configuration without downtime. If an update fails, Deployments support easy rollbacks to a previous known-good state.
- Scaling:
· Deployment: While Deployments are primarily focused on managing the deployment and update process, they internally use ReplicaSets to ensure the desired number of replicas (Pods) are running.
- Example Deployment Definition:
ReplicaSet:
- Purpose:
· ReplicaSet: The primary purpose of a ReplicaSet is to ensure a specified number of replicas (Pods) are running at all times. It helps maintain the desired number of Pod instances and is often used by higher-level controllers like Deployments.
- Imperative Updates:
· ReplicaSet: While ReplicaSets can be used to scale the number of replicas, they lack the declarative update capabilities provided by Deployments. They are more focused on maintaining a fixed number of replicas and don't have native support for declarative updates or rollbacks.
- Selectors:
· ReplicaSet: It uses label selectors to identify the Pods it is responsible for. The label selectors define the set of Pods that the ReplicaSet should manage.
- Scaling:
· ReplicaSet: It allows for manual scaling by updating the replicas field in its specification. However, it does not have built-in support for rolling updates or rollbacks.
- Example ReplicaSet Definition:
Relationship:
· Deployment and ReplicaSet: Deployments use ReplicaSets internally. When you create a Deployment, it creates and manages one or more ReplicaSets to ensure the desired number of replicas are running. The Deployment controls the update process and facilitates rolling updates and rollbacks.
Q 6.Can you explain the concept of rolling updates in Kubernetes?
In Kubernetes, rolling updates are a mechanism for updating a deployment or application without causing downtime. The rolling update process ensures that the new version of the application is gradually deployed across the cluster while maintaining a specified number of available and healthy instances.
Here is how the rolling update process works in Kubernetes:
- Desired State Declaration:
· The desired state of the application is declared in a deployment manifest, typically using a YAML file. This manifest includes information such as the container image, replicas, labels, and other configuration settings.
- Deployment Creation:
· The deployment controller creates a new ReplicaSet based on the updated deployment manifest. This new ReplicaSet represents the desired state of the application.
- Scaling Up New ReplicaSet:
· The controller gradually increases the number of replicas in the new ReplicaSet while decreasing the replicas in the old ReplicaSet. This is done in a controlled and configurable manner, allowing for a smooth transition.
- Pod Termination in Old ReplicaSet:
· As the new replicas become ready, the controller starts terminating the old Pods in a controlled fashion. The number of old Pods being terminated is balanced with the increasing number of new Pods, ensuring that there is no sudden drop in application availability.
- Continuous Monitoring:
· Throughout the rolling update process, Kubernetes continuously monitors the health of the Pods. If any new Pod fails to start or if the health checks fail, Kubernetes can automatically roll back the update to the previous version.
- Completion of Update:
· Once all the replicas in the new ReplicaSet are ready and the old Pods have been terminated, the rolling update is considered complete. The application is now running the updated version.
Key Benefits of Rolling Updates:
- Zero Downtime:
· Rolling updates allow updates to be applied without causing downtime. At any point in time during the update process, a certain number of replicas are available and serving traffic.
- Controlled and Gradual:
· The rolling update process is gradual and controlled. It ensures that the application's availability is maintained, and any potential issues can be identified and addressed early in the update process.
- Automatic Rollback:
· Kubernetes provides automatic rollback in case of issues during the update. If the health checks fail for the new Pods, Kubernetes can automatically revert to the previous version, minimizing the impact on users.
Example Rolling Update Manifest:
Here's a simplified example of a rolling update manifest for a Deployment in Kubernetes:
Q 7.How does Kubernetes handle network security and access control?
Kubernetes provides several mechanisms to handle network security and access control, ensuring that communication between components within the cluster is secure and controlled. Here are some key aspects of network security and access control in Kubernetes:
1. Network Policies:
· Definition: Network Policies are Kubernetes resources that define rules specifying how Pods are allowed to communicate with each other.
· Purpose: Network Policies help control the flow of traffic between Pods, allowing fine-grained access control based on criteria such as pod selectors, namespaces, and IP blocks.
· Example Network Policy:
2. Service Account Permissions:
· Definition: Service accounts are used to control the permissions and access level of Pods.
· Purpose: By default, Pods run with a service account that has a set of default permissions. You can create custom service accounts and associate them with specific Pods, providing different levels of access to Kubernetes resources.
3. RBAC (Role-Based Access Control):
· Definition: RBAC is a Kubernetes feature that allows administrators to define roles and role bindings to control access to resources.
· Purpose: RBAC enables fine-grained control over who can perform actions (create, get, list, delete, etc.) on specific resources within the cluster. Roles define sets of permissions, and role bindings associate those roles with specific users, groups, or service accounts.
4. Pod Security Policies:
· Definition: Pod Security Policies (PSP) define a set of conditions that Pods must adhere to in order to be accepted into the system.
· Purpose: PSP helps enforce security-related configurations, such as running Pods as non-root users, restricting the use of host namespaces, and controlling the use of privileged containers.
5. Secrets and ConfigMaps:
· Definition: Kubernetes provides resources like Secrets and ConfigMaps to manage sensitive information (such as API keys, certificates, and configuration data) separately from the Pod specifications.
Q 8.Can you give an example of how Kubernetes can be used to deploy a highly
available application?
· To deploy a highly available application in Kubernetes, you can use multiple replicas of your application components distributed across different nodes. Employing features like Deployments, StatefulSets, and LoadBalancers ensures redundancy, fault tolerance, and even distribution of traffic. Additionally, using persistent storage for stateful applications ensures data persistence in the event of pod failures.
Q 9.What is namespace is kubernetes? Which namespace any pod takes if we don't specify any namespace?
A Kubernetes namespace is a way to divide cluster resources between multiple users, teams, or projects. If a pod doesn't specify a namespace, it is placed in the default namespace. The default namespace is where resources are created if no namespace is explicitly specified during deployment.
Q 10.How ingress helps in kubernetes?
In Kubernetes, Ingress is an API object that provides external access to services within a cluster. It acts as a traffic manager, routing external requests to the appropriate services based on defined rules. Ingress allows txhe definition of rules for path-based routing, SSL termination, and load balancing, providing a centralized and flexible way to manage external access to applications.
Q 11.Explain different types of services in kubernetes?
Kubernetes supports various service types, including ClusterIP, NodePort, LoadBalancer, and ExternalName.
· ClusterIP: Exposes the service only within the cluster.
· NodePort: Exposes the service on a static port on each node.
· LoadBalancer: Exposes the service externally using a cloud provider's load balancer.
· ExternalName: Redirects the service to a DNS name.
Each service type caters to different use cases and requirements.
Q 12.Can you explain the concept of self-healing in Kubernetes and give examples of how it works?
Self-healing in Kubernetes refers to the system's ability to automatically recover from failures. If a pod or node fails, Kubernetes can automatically reschedule the pod to a healthy node. Additionally, features like liveness and readiness probes help identify and address issues with individual containers within a pod, ensuring continuous operation.
Q 13.How does Kubernetes handle storage management for containers?
Kubernetes manages storage using Persistent Volumes (PVs) and Persistent Volume Claims (PVCs). PVs represent physical storage resources in the cluster, while PVCs are requests for storage by users. Pods can use PVCs to access persistent storage, allowing data to persist even if a pod is rescheduled to a different node.
Q 14.How does the NodePort service work?
NodePort is a service type in Kubernetes that exposes the service on a static port on each node in the cluster. When external traffic reaches any node on that port, the NodePort service forwards it to the corresponding service within the cluster. This provides external access to services without requiring an external load balancer.
Q 15.What is a multinode cluster and single-node cluster in Kubernetes?
A multinode cluster in Kubernetes consists of multiple worker nodes, each running containerized applications. It allows for distribution of workloads, redundancy, and scalability. In contrast, a single-node cluster runs all Kubernetes components, including worker and control plane, on a single machine. Single-node clusters are typically used for development or testing purposes.
Q 16.Difference between create and apply in kubernetes?
in Kubernetes, kubectl create is used to create a resource based on a file or command-line arguments, while kubectl apply is used to either create a new resource or update an existing one. apply is preferred for managing resources over time because it can apply incremental changes to resources, making it more suitable for declarative configuration and continuous delivery workflows.




